

1、购买:一次偶然的选择
自从看了Linus的视频[8],我就想亲自上手一下这款A100同款芯片的卡。然而之前我问过的几个贩子要么不理我,要么就表示不单出。所以我直到最近才拿到这张卡。刚好那个贩子手上只有这一张卡了。我购入的价格是2850元,加上上散热器、转接线的80元,硅脂18元,总价近3000元。
先说结论吧,如果不是以研究或者收藏、维修练手为目的,不推荐碰这张卡!!!
首先,就以外观来说,这卡还是很不错的。

2、散热处理:不得不做的前期工作
默认的被动散热很厚实,加上外置风扇的散热效率也很高。如果接受不了外置噪音,可以改水冷。

我使用了从别家购得的A100弯折散热器来给170hx散热。声音有点大,我手上没有分贝仪,大概相当于我的2080TI 涡轮2800-3000转的声音。不过由于风扇是USB供电,可以自行增加可调电阻来改变转速。

我使用迷你主机OCULINK外接显卡坞来测试以及使用这张卡,主要还是因为换卡方便,而且不补电容[9]的话,CMP系列默认都只有PCIE 1.1 X4,补上电容可以到PCIE 1.1 X16。
在通常状态下,170hx的待机功耗约为33W。
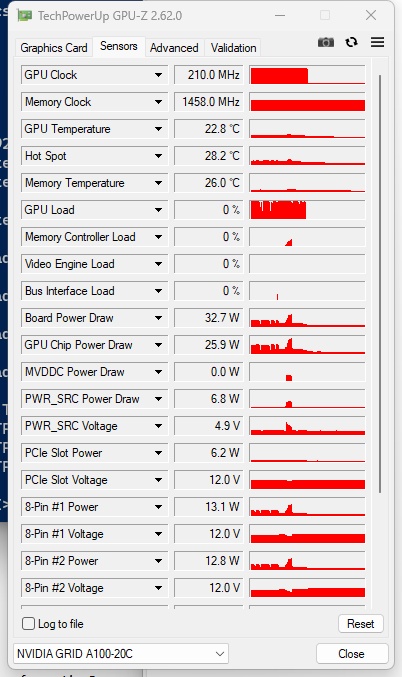
在我更换GD-2导热硅脂后,核心满载温度如下:
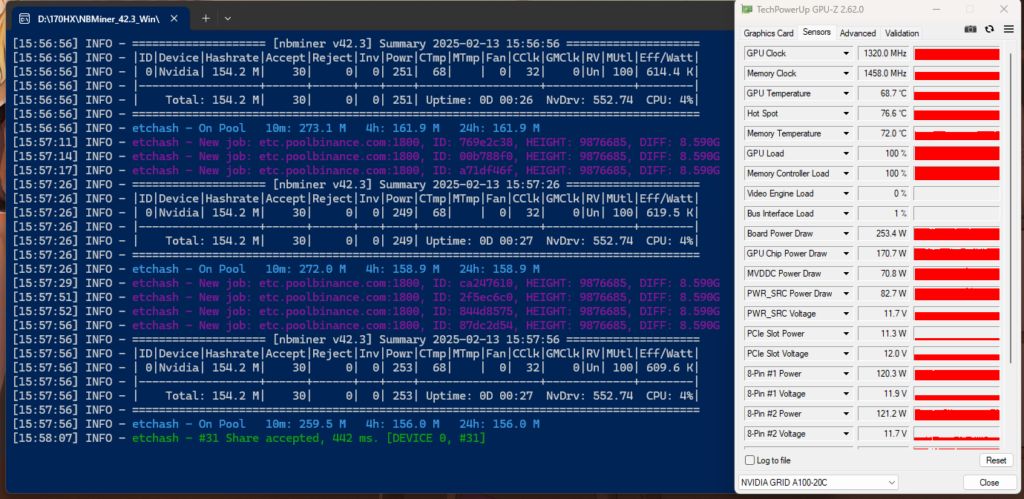
3、驱动安装:神秘的卡要有神秘的装法
NVIDIA CMP 170HX在Windows下需要特别版驱动,我从Linus的视频[8]里看到可以从Vipera官网[10]下载.
但是,下载的驱动版本很低,是471.50.自带的CUDA版本仅为11.4,所以还得自己想办法升级驱动。
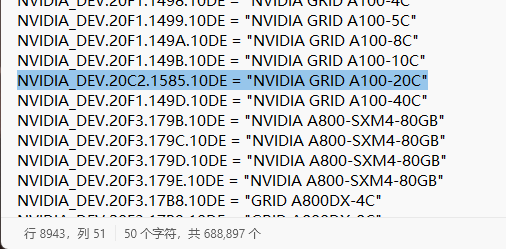
按照百度贴吧的教程[5],我下载了552.74 版GRID驱动[11]。把它解压出来,之后修改Display.Driver文件夹下的nvgridsw.inf文件。记录下NVIDIA GRID A100-20C对应的ID NVIDIA_DEV.20F1.149C.10DE,将它替换为170HX的ID(可以在设备管理器-170HX-详细信息-硬件ID里找到,我的是PCI\VEN_10DE&DEV_20C2&SUBSYS_158510DE)。注意格式应与修改前保持一致。换句话说,就是用20C2.1585.10DE来替换20F1.149C.10DE,以及在文件前面一处用DEV_20C2&SUBSYS_158510DE替换DEV_20F1&SUBSYS_149C10DE。
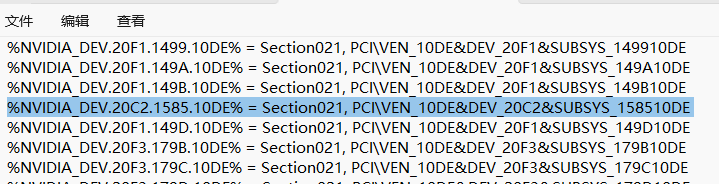
修改好驱动程序之后,我必须要禁用驱动程序签名[12]才能安装这个自己修改的驱动。我选择通过高级启动来临时禁用一次,接着就可以在设备管理器上右键170HX-更新驱动程序-浏览电脑-定位到Grid驱动解压的路径-下一步,在弹出的窗口中选择无视风险继续安装。
安装完成后,CUDA版本就是12.4了,就可以尝试一些比较新的CUDA应用了。
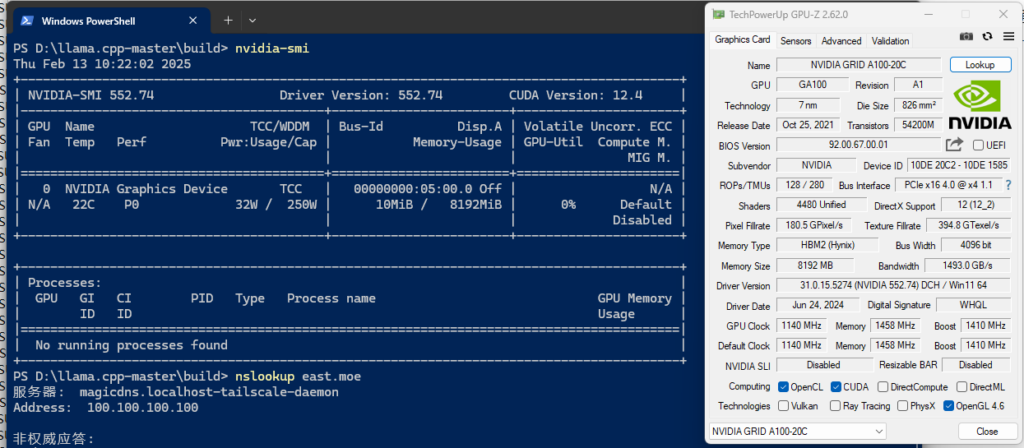
需要注意的是,这卡不支持WDDM,仅能工作在TCC模式下,NVIDIA-SMI无法修改模式,强制修改注册表开启WDDM会导致掉驱动。
4、算力测试:被废除了武功的GA100
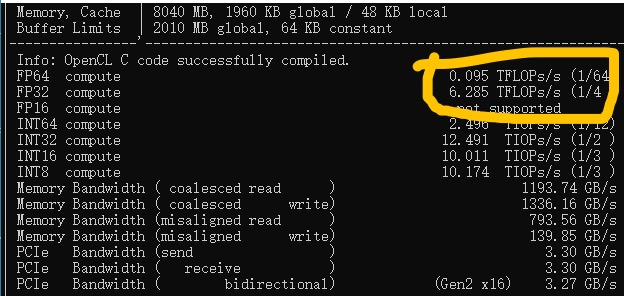
以下是默认状态下的一些测试。
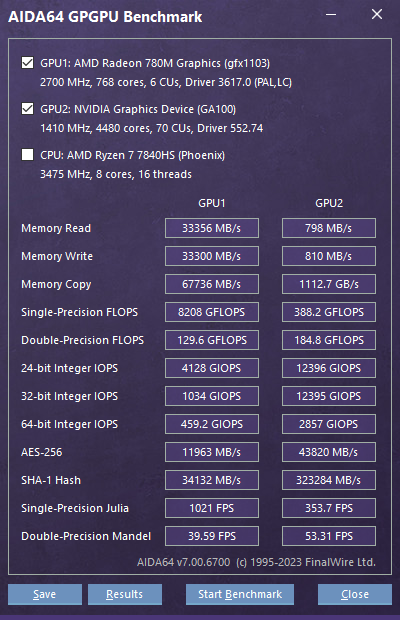
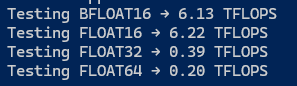
一篇知乎专栏[2]中提到了如上的浮点算力的异常。至于整数的情况,貌似没有被阉割。一位GitHub用户在他的90HX上也发现了类似的情况[4]。他发现RTX GPU的 FP32=(当前卡的FP64x64),而CMP GPU的 FP32=(当前卡的FP64x2)
。
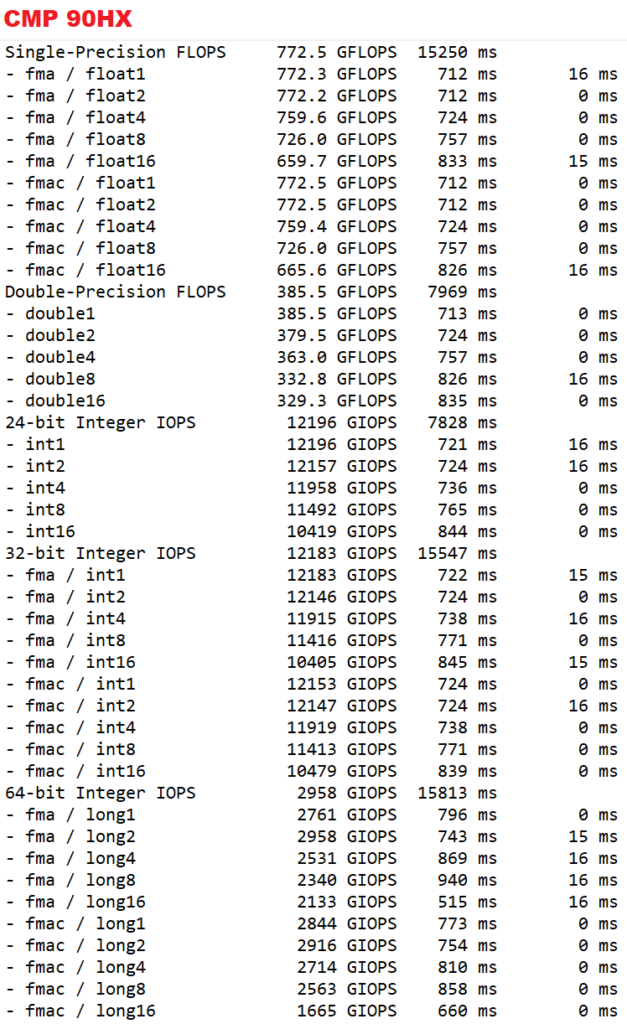
不过,我测试的情况与他的90HX稍有不同,我想分情况讨论一下。
4.1、FP32
FP32是大部分游戏以及早期机器学习所需要的算力。CMP系列里除了30HX\40HX外,其余的卡都对它施加了严格的限制。390Gflops的FP32算力约等于GTS240或Intel UHD Graphics 630的FP32算力
170HX在运行FP32负载时,功耗约为60W,GPU占用为100%。
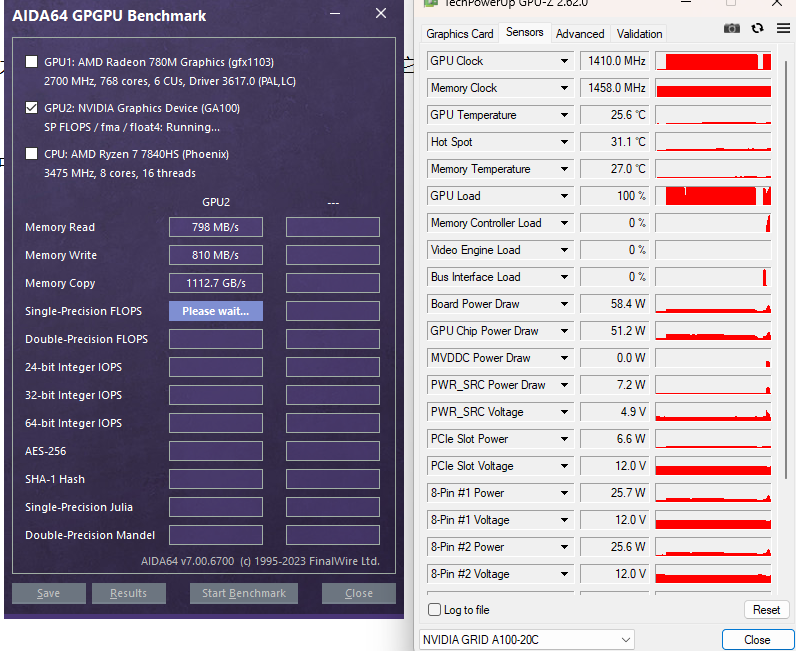
GPU Database上推算出的170HX FP32理论算力为12.63 TFLOPS。
4.2、FP16
目前深度学习推理(特别是Stable Diffusion等图像生成模型)的主要推理精度。经过我的测试,170HX约有6.2Tflops的FP16算力。约等于RX580 2304SP的FP16算力或GTX1070的FP32算力。
170HX在运行FP16负载时,功耗约为75W,GPU占用100%。
GPU Database上推算出的170HX FP16理论算力为50.53 TFLOPS (4:1)。
4.3、BF16
作为Ampere架构的“集大成者”,GA100当然应该支持BF16混合精度计算。
不过,170HX的BF16同样遭到了阉割,算力只有6.13Tflops,和FP16算力差不多。
在执行BF16的负载时,功耗不到70W,GPU占用为100%。
4.3、FP64
FP64主要用于科学计算,如HPC。170HX的FP64被阉割到了和Geforce卡差不多的水平。184.5Gbps的FP64算力约等于RTX2060的FP64算力。
在计算FP64时,170HX功耗约为60W,GPU占用约为100%
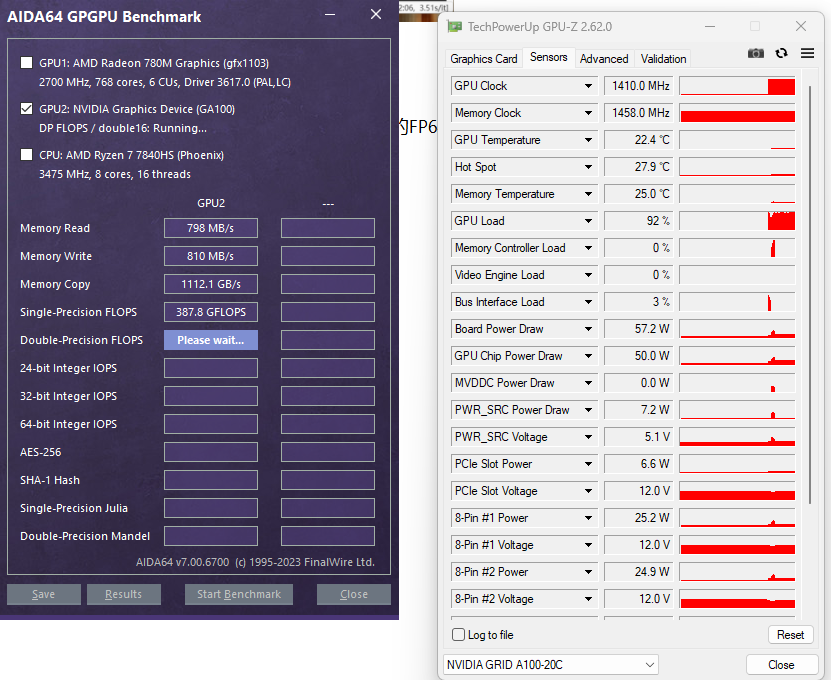
GPU Database上推算出的170HX FP64理论算力为6.317 TFLOPS (1:2)。
4.4、整数
整数推理在机器学习中用到的不多,我记录了长整型(INT64)的负载情况。
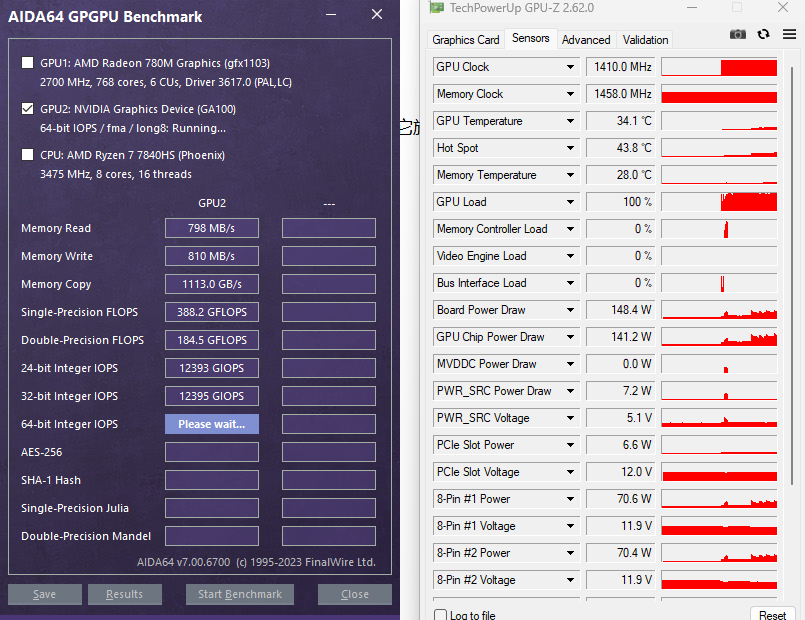
可以看出,我之前认为“整数部分没有动刀子”是错误的。区别在于阉割的多还是少。在INT64负载压力下,功耗只有150W左右,GPU占用依旧为100%。
4.5、哈希计算
EThash的计算依赖于哈希,所以哈希计算是少数能使得GPU接近满载的负载。
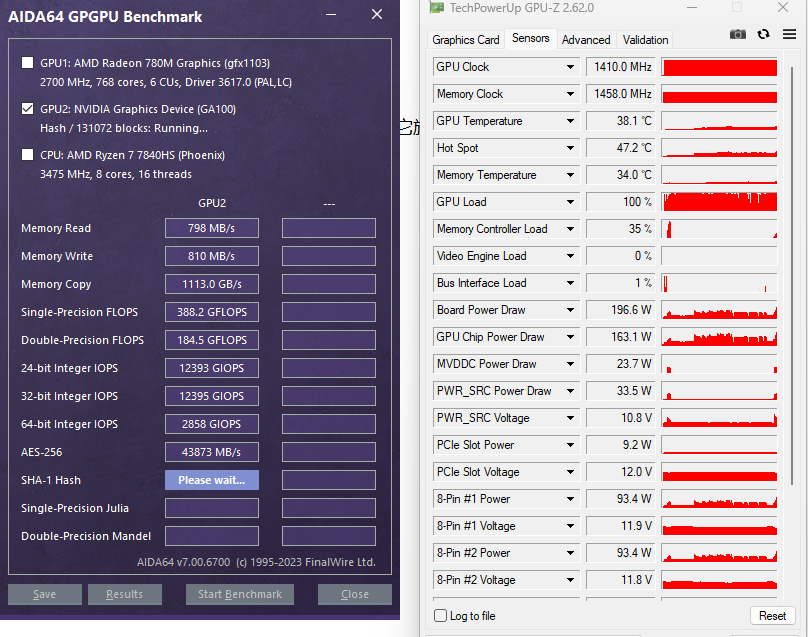
不过,应该没有人买这卡只是为了进行除了挖矿之外的哈希计算以及密码破解的吧?没有吧?
4.6、ETHash算力
聊胜于无把,我用这卡尝试挖了一会儿ETC,或许是因为网络问题,并不能达到标称的164MH/s。通常情况下,算力在150-160MH/s之间。上面的压力测试那里也有图,就不重复放了。能够跑满250W TDP。不过根据视频[8]里的说法,可以把它的TDP降低至20W而几乎维持算力不变,这样能耗比更高。
5、llama.cpp:整数还是浮点?
到目前为止,这卡对于我来说,似乎除了外观好看外加这颗“名不副实”的GA100核心之外,也只能低功耗跑一下SD或是SDXL的中低分辨率图像的用处了。但就在我打算放弃并且想办法把它当成电子手办清理好摆起来的时候,一次偶然的尝试却激起了我的好奇心。
虽然我已经知道170HX在整数性能上没有阉割的那么狠,但是我之前所使用的各种AI应用几乎都是基于浮点计算的。在我尝试各种AI应用的时候,llama.cpp却给了我一个惊喜。
在使用llama-b4705-bin-win-cuda-cu12.4-x64这个Release版推理tifa-7b-qwen2-v0.1.q6_k.gguf这个模型的时候,我发现GPU功耗趋向了130W左右,而且生成速度有大约35 tokens/s。(PS:执行的命令为:./llama-server -m D://llamacpp/models//tifa-7b-qwen2-v0.1.q6_k.gguf --port 8080 -ngl 29)
联想起之前的测试结果,我只能得出一个结论,即llama.cpp执行了整数计算。
此刻,我的好奇心被完全激发起来了,产生了2个疑问:
- llama.cpp能够进行整数计算,是否需要特定的模型?
- 我是否可以通过自定义参数运行llama.cpp,甚至自行编译它,来让这些模型完全运行在整数计算上?
5.1、问题1:是特定的模型吗?
我使用了另外两个模型做测试,下面是agentica-org_DeepScaleR-1.5B-Preview-Q8_0.gguf的测试结果:
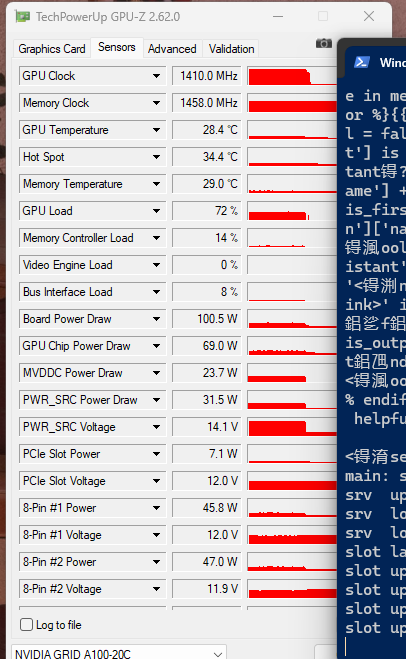
下面是agentica-org_DeepScaleR-1.5B-Preview-f16.gguf的测试结果
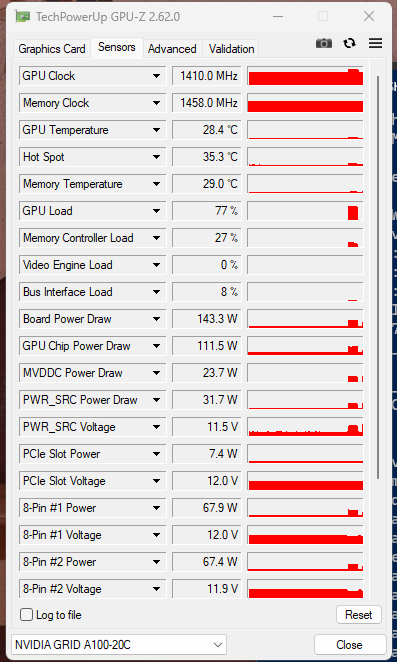
我个人发现,不同量化等级的模型,可以在170HX上跑出完全不一样的功耗。说明LLAMA.CPP对于不同的模型使用不同的计算方案,这会导致涉及整数计算的部分不同,在170HX这张奇葩的卡上就导致了GPU利用率的不同。
5.2、问题2:是特定的参数吗?
llama.cpp官方在涉及CUDA的编译指南[14]中给我提供了几个参数,可以用来控制计算精度。
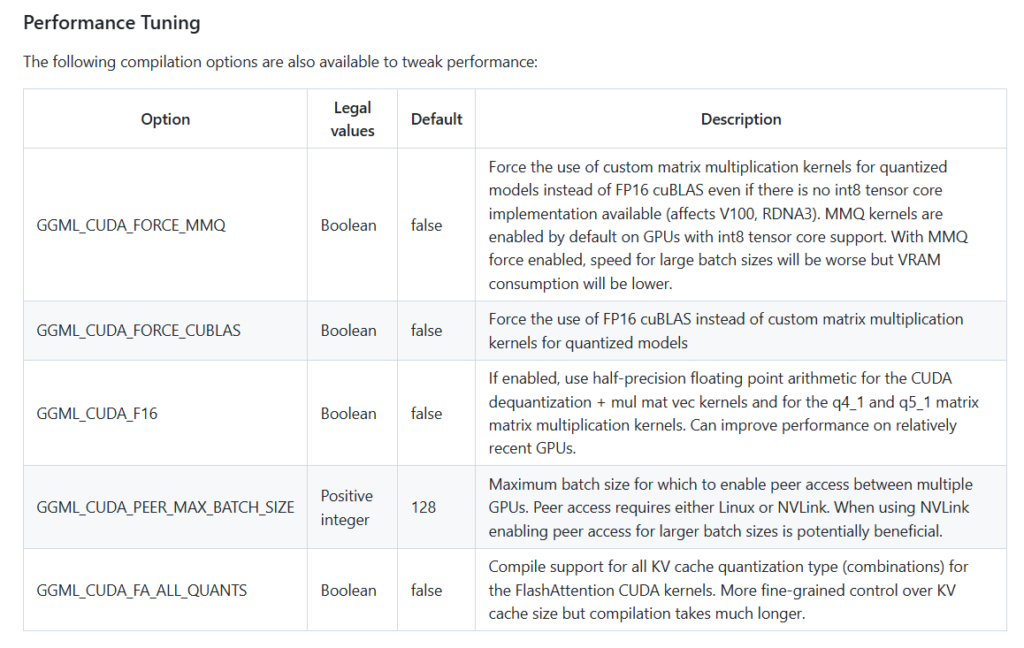
不过我并不知道我用的发行版里用了什么编译参数,或许我可以考虑自己编译一个?
但不管怎么说,在解决了上面两个困惑之后,我觉得这卡的用处或许还有配合自己编译的llama.cpp来跑一些要求不高的低参数LLM。
6、FMA:被幕后黑手利用的工具
在查找资料的过程中,我发现了前一位探索者的步伐。有一位知乎用户购买了170HX,并且发现在禁用了FMA之后,可以恢复一半的单精度算力[3]。
在他的试验中,使用去除了FMA的clpeak可以让170HX的FP32算力达到近6.3Tflops。这大致相当于GPU Database上标称的FP32算力12.63 TFLOPS的一半。
乘加融合运算 FMA(Fused Multiply-Add)是一种硬件指令,能够在单个操作中执行乘法和加法运算,形式为 a * b + c。同时,FMA在中间结果不进行舍入的情况下直接进行加法运算,提高了计算精度,减少了累积误差。禁用FMA后,乘法和加法需要分开执行,增加了指令数量和延迟,导致性能下降。中间结果会进行舍入,可能导致累积误差增加,影响计算精度。——DeepSeek V3
按照解释,FMA可以用来提升运算速度和精度,但是nVidia居然把它用在了限制矿卡的浮点运算能力上。但关键问题在于,除非破解驱动,否则大家无法轻易地禁用FMA。而如果可以破解驱动,那为什么不直接让FMA恢复正常呢?
很多深度学习以及依赖CUDA计算地应用都需要FMA。对于开源程序,大家可以尝试在编译时禁用它来恢复一定的性能[4]:
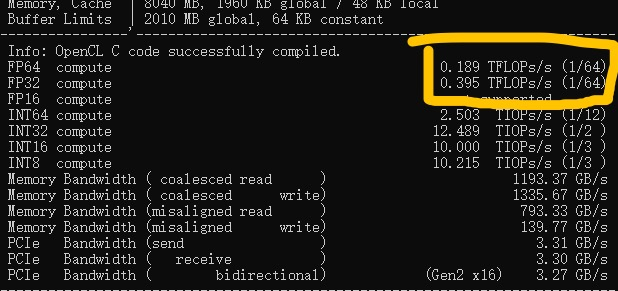
但是就算是开源的CUDA程序,也有很大可能存在依赖FMA的代码,必须手工去除。好在深度学习对于精度的要求不高,不太需要担心禁用FMA后导致的误差累积。但就算如此,优化这么多程序的代码然后再把它们编译出来,这放在任何个人而非组织身上都是一项艰巨的任务。
这位知乎答主[3]修改了FluidX3D的代码,使得170HX在这款工具上的算力达到了RTX4090的1.4倍。
6.1、可能的猜测与大胆的实践
在那篇知乎专栏中,答主提到了修改源代码,使用类似于
/* 用宏覆盖 OpenCL 的内建 fma() 与 mad() 函数 */
#define fma(a, b, c) ((a) * (b) + (c))
#define mad(a, b, c) ((a) * (b) + (c))
/* 禁用自动 FMA 和 MAD 优化 */
#pragma OPENCL FP_CONTRACT OFF的宏来禁用FMA。
除此之外,在编译时,可以通过向nvcc传递 -fmad=false 来让CUDA编译器禁用FMA。但是考虑到很多常用的优化选项会自行开启FMA,所以这位博主也提到了自行设计一个编译器中介体来负责对接程序和nvcc等编译器,并防止它们在优化中开启FMA。但我和博主一样,认为这一方法难度过高。
不过,也有更加大胆的人选择直接对驱动动手,但是很可惜没有成功。
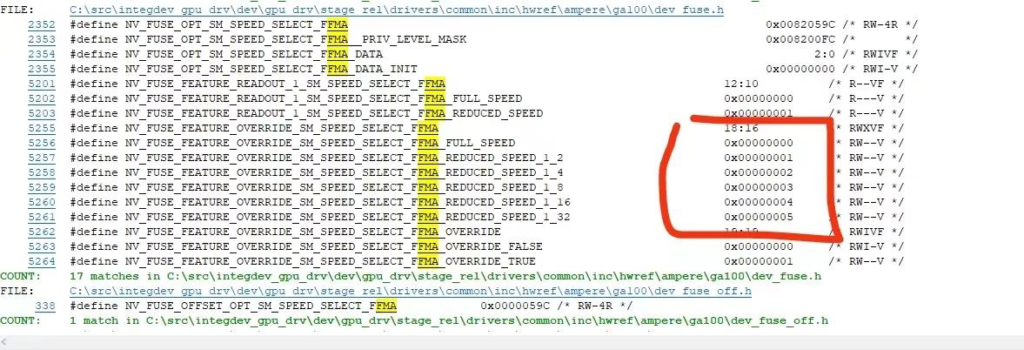
感觉对fma和mad指令的限制,驱动被黄皮刀客做手脚的嫌疑最大啊,驱动检测到特定设备id就拒绝对指令的调用,这跟封禁矿卡玩游戏一个思路,我用二进制编辑器看过一些sys和dll,里边0700开头例如0700071C之类的一大堆包括170HX的id0700C220都在里边,把他们篡改过后(我是把他们全改成0700FFFF)就能强装驱动打开direct compute......efuse烧出来的值对应fma该以1/2n次幂的倍率运行中的n,这个规则在驱动的几个dll文件里边都有,只要能找到规则字段,不管什么efuse值统统full speed这样修改,就能解封FMA......居然不是通过检测id来实现fma调速的,是efuse烧写值,驱动读到,按照烧出来的1/2n次幂降速...... ——知乎用户Alexwewewe
7、我的尝试:禁用FMA编译llama.cpp
获知了以上信息,我决定来自己做一个实验。
我在电脑上安装了VS2022的C++生成工具、Windows 11 SDK、CUDA Toolkit 12.4和cudnn,并配置好了环境变量。
然而,因为我并没有系统接触过编程,只能一边不停尝试一边问Gemini,最终成功编译了我的无FMA的llama.cpp。
参照文档上的build指南和Gemini,我使用了以下编译参数:
>cmake .. -G "Visual Studio 17 2022" -A x64 -DGGML_CUDA=ON -DCMAKE_CUDA_FLAGS="-DFMA_DISABLED" -DGGML_CUDA_F16=ON -DGGML_CUDA_FA_ALL_QUANTS=ON
>cd ..
>cmake --build build --config Release --parallel 16根据我的测试,这个llama.cpp可以在推理tifa-7b-qwen2-v0.1.q6_k.gguf时将显卡功耗推到170W以上:
测试命令:
./llama-server -m D://llamacpp/models//tifa-7b-qwen2-v0.1.q6_k.gguf --port 8080 -ngl 29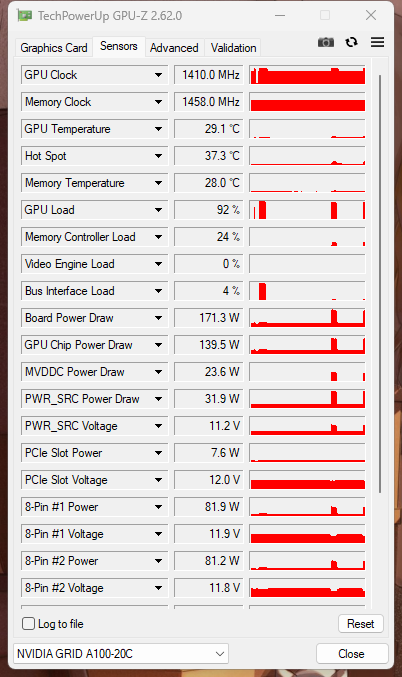
同时,推理速度由原来的25tokens/s提升至大约50tokens/s。
以下是另一个模型的测试:
模型名称: Tifa-DeepsexV2-7b-Q6_K
| llama.cpp 版本 | 功耗 (W) | Tokens/s |
|---|---|---|
| llama-b4689-bin-win-cuda-cu12.4-x64 (Github Release) | 120W | 33 |
| llama-cpp-b4604-without-fma-cu124-win64 (禁止FMA) | 160W | 44 |
后面,我又陆续尝试了多种编译参数,总计尝试编译了不下30个版本但是均未达到这种效果。
| 序列号 | CMake 命令 | 170HX测试速度(tifa-7b-qwen2-v0.1.q6_k.gguf) | 注释 |
|---|---|---|---|
| 1 | cmake .. -G "Visual Studio 17 2022" -A x64 -DGGML_CUDA=ON -DCMAKE_CUDA_FLAGS="-DFMA_DISABLED" -DGGML_CUDA_F16=ON -DGGML_CUDA_FA_ALL_QUANTS=ON | 50t/s | 禁用 FMA (Fused Multiply-Add) 指令集,并启用 FP16 (半精度浮点) 支持。 |
| 2 | cmake .. -G "Visual Studio 17 2022" -A x64 -DGGML_CUDA=ON -DCMAKE_CUDA_FLAGS="-DFMA_DISABLED" -DGGML_CUDA_FORCE_MMQ=ON -DGGML_CUDA_FA_ALL_QUANTS=ON | 35t/s | 禁用 FMA,并强制使用 MMQ (矩阵-矩阵乘法量化) 进行整数运算。 |
| 3 | cmake .. -G "Visual Studio 17 2022" -A x64 -DGGML_CUDA=ON -DCMAKE_CUDA_FLAGS="-DFMA_DISABLED" -DGGML_CUDA_FORCE_CUBLAS=ON -DGGML_CUDA_F16=ON -DGGML_CUDA_FA_ALL_QUANTS=ON | 35t/s | 禁用 FMA,强制使用 cuBLAS 库进行 FP16 运算,并启用 FP16 支持。 |
| 4 | cmake .. -G "Visual Studio 17 2022" -A x64 -DGGML_CUDA=ON -DGGML_CUDA_FORCE_MMQ=ON -DGGML_CUDA_FA_ALL_QUANTS=ON | 35t/s | 不禁用 FMA,但强制使用 MMQ 进行整数运算。 |
| 5 | cmake .. -G "Visual Studio 17 2022" -A x64 -DGGML_CUDA=ON -DGGML_CUDA_FORCE_CUBLAS=ON -DGGML_CUDA_F16=ON -DGGML_CUDA_FA_ALL_QUANTS=ON | 35t/s | 不禁用 FMA,强制使用 cuBLAS 库进行 FP16 运算,并启用 FP16 支持。 |
| 6 | cmake .. -G "Visual Studio 17 2022" -A x64 -DGGML_CUDA=ON -DGGML_CUDA_F16=ON -DGGML_CUDA_FA_ALL_QUANTS=ON | 35t/s | 不禁用 FMA,仅启用 FP16 支持。 |
| 7 | cmake .. -G "Visual Studio 17 2022" -A x64 -DGGML_CUDA=ON -DGGML_CUDA_FORCE_MMQ=ON -DGGML_CUDA_F16=ON -DGGML_CUDA_FA_ALL_QUANTS=ON | 35t/s | 不禁用 FMA,强制使用 MMQ 进行整数运算,并启用 FP16 支持。 |
| 8 | cmake .. -G "Visual Studio 17 2022" -A x64 -DGGML_CUDA=ON -DCMAKE_CUDA_FLAGS="-DFMA_DISABLED -gencode arch=compute_80,code=sm_80 -O3" -DCMAKE_CUDA_ARCHITECTURES=80 -DCMAKE_BUILD_TYPE=Release -DCMAKE_CUDA_COMPILER_FORCED=ON -DGGML_CUDA_F16=ON -DGGML_CUDA_FA_ALL_QUANTS=ON | 35t/s | 禁用 FMA,启用 FP16,针对 GA100 架构 (compute_80, sm_80) 优化,使用 -O3 优化级别,Release 编译模式,并跳过 CUDA 编译器测试。 |
| 9 | cmake .. -G "Visual Studio 17 2022" -A x64 -DGGML_CUDA=ON -DCMAKE_CUDA_FLAGS="-DFMA_DISABLED -gencode arch=compute_80,code=sm_80 " | 35t/s | 禁用 FMA,启用 FP16,针对 GA100 架构 (compute_80, sm_80) 优化,Release 编译模式,并跳过 CUDA 编译器测试。优化级别默认为 -O2。 |
| 10 | cmake .. -G "Visual Studio 17 2022" -A x64 -DGGML_CUDA=ON -DCMAKE_CUDA_FLAGS="-DFMA_DISABLED -O3" -DCMAKE_CUDA_ARCHITECTURES=80 -DCMAKE_BUILD_TYPE=Release -DCMAKE_CUDA_COMPILER_FORCED=ON -DGGML_CUDA_F16=ON -DGGML_CUDA_FA_ALL_QUANTS=ON | 35t/s | 禁用 FMA,启用 FP16,针对 GA100 优化,使用 -O3 优化级别,Release 编译模式,并跳过 CUDA 编译器测试。架构优化依赖于通用优化。 |
| 11 | cmake .. -G "Visual Studio 17 2022" -A x64 -DGGML_CUDA=ON -DCMAKE_CUDA_FLAGS="-DFMA_DISABLED " | 35t/s | 禁用 FMA,启用 FP16,针对 GA100 优化,Release 编译模式,并跳过 CUDA 编译器测试。架构优化和通用优化均依赖于默认设置。 |
| 12 | cmake .. -G "Visual Studio 17 2022" -A x64 -DGGML_CUDA=ON -DCMAKE_CUDA_FLAGS="-DFMA_DISABLED -O2" -DCMAKE_CUDA_ARCHITECTURES=80 -DCMAKE_BUILD_TYPE=Release -DCMAKE_CUDA_COMPILER_FORCED=ON -DGGML_CUDA_F16=ON -DGGML_CUDA_FA_ALL_QUANTS=ON | 35t/s | 禁用 FMA,启用 FP16,针对 GA100 优化,使用 -O2 优化级别,Release 编译模式,并跳过 CUDA 编译器测试。 |
| 13 | cmake .. -G "Visual Studio 17 2022" -A x64 -DGGML_CUDA=ON -DCMAKE_CUDA_FLAGS="-DFMA_DISABLED -O1" -DCMAKE_CUDA_ARCHITECTURES=80 -DCMAKE_BUILD_TYPE=Release -DCMAKE_CUDA_COMPILER_FORCED=ON -DGGML_CUDA_F16=ON -DGGML_CUDA_FA_ALL_QUANTS=ON | 35t/s | 禁用 FMA,启用 FP16,针对 GA100 优化,使用 -O1 优化级别,Release 编译模式,并跳过 CUDA 编译器测试。 |
| 14 | cmake .. -G "Visual Studio 17 2022" -A x64 -DGGML_CUDA=ON -DCMAKE_CUDA_FLAGS="-DFMA_DISABLED " -DCMAKE_CUDA_ARCHITECTURES=80 -DCMAKE_CUDA_COMPILER_FORCED=ON -DGGML_CUDA_F16=ON -DGGML_CUDA_FA_ALL_QUANTS=ON | 35t/s | 禁用 FMA,启用 FP16,针对 GA100 优化,并跳过 CUDA 编译器测试。架构优化依赖于 -DCMAKE_CUDA_ARCHITECTURES=80。 |
| 15 | cmake .. -G "Visual Studio 17 2022" -A x64 -DGGML_CUDA=ON -DCMAKE_CUDA_FLAGS="-DFMA_DISABLED " -DCMAKE_CUDA_ARCHITECTURES=80 -DCMAKE_CUDA_COMPILER_FORCED=ON -DGGML_CUDA_F16=ON -DGGML_CUDA_FA_ALL_QUANTS=ON | 35t/s | 禁用 FMA,针对 GA100 优化,跳过 CUDA 编译器测试,并启用 FP16 支持。架构优化依赖于 -DCMAKE_CUDA_ARCHITECTURES=80。 |
| 16 | cmake .. -G "Visual Studio 17 2022" -A x64 -DGGML_CUDA=ON -DCMAKE_CUDA_FLAGS="-DFMA_DISABLED -USE_FAST_MATH" -DGGML_CUDA_F16=ON -DGGML_CUDA_FA_ALL_QUANTS=ON | 35t/s | 禁用 FMA,启用快速数学库 (-USE_FAST_MATH),并启用 FP16 支持。 |
我怀疑是自己运气好呢,还是不好呢,还是水平太低了呢....
8、未来:困难但初显曙光
虽然我没有完全了解nVidia驱动的运作原理(PTX转译为机器码的过程是完全不公开的),但是我至少为这张高达3000元的170HX找到了一个不那么适合它,但勉强能胜任的工作。
大家都知道矿卡的算力锁在于FMA的转译过程中,而且目前有那么几条可行的路径,以群众的智慧,我相信未来会有更多的能够利用上这些锁算力的矿卡的工具。而目前还是一团迷雾的Tensor Core、VBIOS、PCIE版本锁定等,只能期待更多的人前来探索了。
最后,祝愿看到这篇文章的人,新年要开开心心的哦!
EXP.1、另一次没有成功的尝试
在编译llama.cpp并成功将170HX功耗推至170W之后,我尝试编译过Pytorch,但是它复杂的第三方模块在禁用FMA编译的条件下让我陷入了BUG深渊。为了获得较快的SD推理速度,我把主意打到了stable-diffusion. cpp上。我修改了stable-diffusion.cpp/ggml/CMakeLists.txt:
...
option(GGML_FMA "ggml: enable FMA" OFF) # line106
...
option(GGML_CUDA "ggml: use CUDA" ON) # line 129
...
option(GGML_CUDA_F16 "ggml: use 16 bit floats for some calculations" ON) # line 133
...
修改了stable-diffusion.cpp/ggml/src/ggml-cuda/CMakeLists.txt:
...
set(CMAKE_CUDA_ARCHITECTURES "80") # line16
...
set(CUDA_FLAGS --fmad=false) # line 102
...使用了如下的编译命令:
cmake .. -DSD_CUDA=ON -DGGML_CUDA=ON -G "Visual Studio 17 2022" -A x64 -DCUDA_NVCC_FLAGS="-DFMA_DISABLED" -DGGML_FMA=OFF -DCMAKE_CUDA_FLAGS="-DFMA_DISABLED" -DGGML_CUDA_F16=ON
cmake --build . --config Release --parallel 16然而,编译完成的sd.exe在进行推理时,170HX的功耗依旧只有80W左右。我尝试过修改或变更参数,都对功耗影响不大。
只能等待进一步的研究了。或许我还可以去试试看别的基于cpp的CUDA推理工具。
EXP.2、更加让人迷惑的详细测试
我对GitHub Release llama.cpp和自己编译的llama.cpp进行了更加详细的测试,但是结果却大大超出了我的预料,让这一切变得扑朔迷离。
硬件 & 驱动信息:
- GPU: NVIDIA CMP 170HX 8GB (GA100-105F-A1)
- 系统: Windows 11 企业版
- Drivers: 552.74 (GRID)
- CUDA: 12.4
| 模型名称 | llama.cpp 版本 | 量化方法 | 功耗 (W) | Tokens/s |
|---|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | llama-cpp-b4604-without-fma-cu124-win64 (禁止FMA) | q2_K | 95W | 88 |
| q4_K_M | 100W | 109 | ||
| q6_K | 115W | 103 | ||
| q8_0 | 115W | 120 | ||
| fp16 | 120W | 69 | ||
| fp32 | 110W | 65 | ||
| llama-b4689-bin-win-cuda-cu12.4-x64 (Github Release) | q2_K | 85W | 76 | |
| q4_K_M | 85W | 78 | ||
| q6_K | 100W | 89 | ||
| q8_0 | 100W | 110 | ||
| fp16 | 135W | 97 | ||
| fp32 | 110W | 65 | ||
| Llama-3.2-3B-Instruct-uncensored | llama-cpp-b4604-without-fma-cu124-win64 (禁止FMA) | IQ3_M | 130W | 93 |
| IQ4_XS | 135W | 92 | ||
| Q2_K | 110W | 66 | ||
| Q4_K_M | 130W | 83 | ||
| q5_k_m | 120W | 74 | ||
| Q6_K | 140W | 75 | ||
| Q8_0 | 150W | 99 | ||
| F16 | 125W | 43 | ||
| llama-b4689-bin-win-cuda-cu12.4-x64 (Github Release) | IQ3_M | 110W | 74 | |
| IQ4_XS | 115W | 85 | ||
| Q2_K | 90W | 48 | ||
| Q4_K_M | 95W | 51 | ||
| Q5_K_M | 100W | 52 | ||
| Q6_K | 105W | 60 | ||
| Q8_0 | 120W | 82 | ||
| F16 | 180W | 80 |
为什么同样是fp16,llama-3.2和Qwen1.5B的性能表现大相径庭?它在禁用FMA之下的Q8_0的表现也很不错。这一切是模型参数、量化的区别?还是算力的问题呢?可是这又与我之前使用Pytorch测试以及comfyui推理时测得的FP16负载只有75W功耗,6TFlops算力不同。而那位知乎答主则说调用CUDA后fp16算力为42T,且不受FMA影响[2]。
这一切让我的脑子更加迷惑。有一个朋友建议我使用Linux进行进一步测试。我打算过几天安装好Ubuntu后再试试吧。
参考
- CMP 170HX 不完全指南. (2021). 知乎.
- 内存带宽拉满,浮点算力砍完——Nvidia CMP 170HX 矿卡评测,以及拆解、部分规避算力限制、水冷改造以及维修方法. (2023). 知乎.
- dartraiden. (n.d.). 170hx (any cmp hx card) can run higher and higher fp32 flops than before. GitHub.
- dartraiden. (n.d.). Questions about CMP 90 HX. GitHub.
- CMP 170HX解锁 AI绘图/3D渲染功能 教程. (2023). 百度贴吧.
- CMP 170hx到手,准备开启折腾之路. (2023). 百度贴吧.
- NVIDIA CMP 170HX 8 GB. (n.d.). TechPowerUp.
- This $5000 Graphics Card Can’t Game - NVIDIA CMP 170HX Mining GPU. (n.d.). YouTube.
- 英伟达CMP 40HX矿卡魔改驱动答疑专栏. (n.d.). Bilibili.
- Downloads _ Smart Pass Facial Recognition _ DC MIPS Smart Pass. (n.d.). ViperaTech.
- NVIDIA 英伟达TESLA计算卡专用驱动 GRID驱动下载链接分享(P40 P100 T4等显卡可用). (n.d.). Bilibili.
- Windows 11 禁用驱动程序强制签名. (n.d.). iyatt 博客.
- llama.cpp_docs_build.md at master · ggerganov/llama.cpp. (n.d.). GitHub.
Comments 2 条评论
这是一条私密评论
这是一条私密评论