

0.前言
以大语言模型(LLM)为代表的AI是自2022年底以来便持续火爆的热点话题。而咱又是个对于自己的数据有着极端掌控欲望的人(有家庭存储服务器并且一直希望能够在自己家里架设一整套社交/聊天/视频/音乐网站)。早在22年12月份我就注册并且体验过了ChatGPT,但是当时使用的高门槛(国外手机号+境外特定原生IP)让我一直提不起太大的兴趣。后买在slack上用了一整子Claude,在写论文时帮了我的大忙,但是后面考虑以下问题,还是决定自己部署一套大语言模型工作流。
- 成本问题:商用闭源AI模型需要支付订阅费用,我个人不是很喜欢订阅制,因为这要求我必须每隔一段时间就支付一次费用,考虑到毕业后几年内工作以及收入的不稳定性,还是趁着资金充裕时一次性购入硬件来部署本地AI更好。
- 定制性限制:闭源模型的内部工作原理和算法细节不公开,这限制了我对其进行定制和优化的能力。相比之下,开源模型允许用户根据特定需求进行修改和扩展。
- 依赖性风险:使用商用的闭源模型意味着对这些供应商的依赖性增加,如果供应商停止服务或更改条款,会对我造成影响。开源模型则可以减少这种依赖性。
- 数据隐私和安全性:使用闭源模型可能需要将数据发送到供应商的服务器上进行处理,这可能引发数据隐私和安全性的担忧。而本地部署的开源模型可以在本地处理数据,更好地控制数据安全。
- 内部限制问题:闭源模型往往有着更加严格的基于道德和法律等问题的限制。开源模型则通常更加宽松,允许我自由生成那些可能违反法律、伦理道德或者NSFW的内容(这个才是重点吗?)。
- 技术锁定:使用闭源模型使我个人陷入技术锁定,难以在AI应用上获得学习与锻炼,包括但不限于丧失更换其他AI平台或技术的能力。而开源模型则提供了更多的灵活性和选择,有助于我个人的学习与成长。
在大语言模型发展了不到两年的时间里,涌现出了许多优秀的开源模型,根据LLM竞技场的人类感知排行榜可知,已经有一些开源LLM的智能赶上了早期的GPT-4。
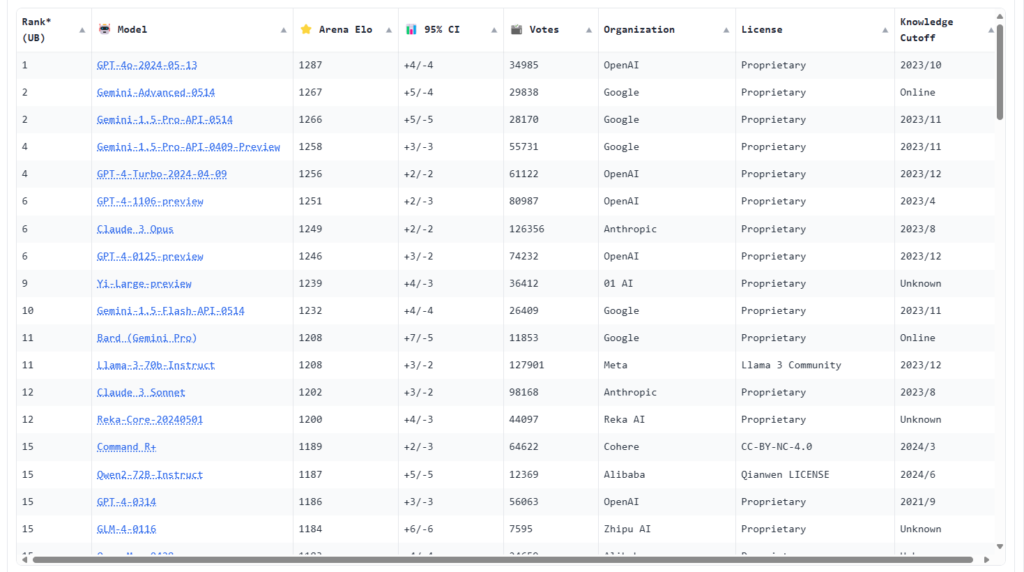
当然,本文的目的不是推荐最好的开源LLM。毕竟这些LLM大部分都有自己明显的优缺点,在Huggingface上还有不少用途特别“专”的模型,例如专注于日文轻小说/游戏翻译的SakuraLLM团队所推出的一些列模型,这里不再具体阐述。
要想在本地部署大语言模型,最重要的便是准备一套硬件(尤其是GPU)。咱有点小小的钱,但是不多,便选择了炼丹丐版组合(RTX2080TI 22G x2)。我的主板不支持4卡,也没有空间安放超微等品牌的GPU服务器,便暂时用自己的台式机过渡一下。
推理框架会影响LLM的推理速度与资源占用。在结合了网上大量的信息之后,我决定使用vllm作为我的推理框架(而不是原生transformer),理由如下:
- 同等条件下vllm的理论推理性能比其他推理框架高一大截(https://arxiv.org/pdf/2309.06180)。
- vllm的部署相对简单(https://docs.vllm.ai/en/latest/getting_started/installation.html)。
- vllm可以直接对外提供服务(以兼容openai api的api向外提供服务)(https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html)。
在明确了上述信息后,我开始搭建GPU服务器,鉴于这是一篇类似于分享的教程,我会尽量详细说明步骤。
1. 硬件组装
这一部分就是将GPU服务器组装起来——参照网上的装机教程就可以解决大部分问题,但是如果你和我一样准备组建多卡平台,这里有一些坑需要注意:
- 确保你的电源功率足够让所有的GPU以及其他硬件正常运行(电源额定功率 > GPU功率 x N + CPU功率 x N + 100+W)。这里留出100W的余量是因为部分GPU服务器自带的远程控制卡/光口网卡或加装多块硬盘/PCIE设备/LED灯等会占用一部分功耗。
- 检查你的内存安插顺序——大部分品牌服务器对于内存安插顺序有严格的要求,轻则性能下降/开机报错或不识别,重则无法开机。
- 检查你的GPU卡类型,多卡平台只推荐涡轮散热或被动散热(其实也不是很推荐被动散热,因为过于吵了)。像网上那种三风扇,外观花里胡哨的游戏卡,在外面组一个开放式多卡平台还好,放在机箱里妥妥过热报错而且吹出的热风还会连累其它硬件。
- LLM的纯推理对于带宽要求不高,但最好还是检查一下主板上PCIE通道的分配情况。在支持双路CPU的主板上,会有一部分PCIE插槽只有安装了全部的CPU才会被启用。建议查询说明书以及调整BIOS设置以尽可能最大化利用所有的PCIE通道。
- 除非你购买了相关的主板或准系统,否则不要买SXM接口的GPU——转接板比GPU本体还贵。
- 如果你确实需要安装nvlink,请检查你的显卡间距——间距过大或过小是安装不上这种硬桥的。
- 不要看LLM很大就觉得可以把它们像存放番剧一样放在机械硬盘里,随用随点——请务必使用SSD。
2. 安装系统
这一部分没有什么好说的,Ubuntu或者Debian都行(个人推荐Ubuntu,因为网上资料更多,出现bug容易排查。但是Debian在软件来源上更加可控一些)。
咱个人使用的是最新版的Ubuntu 22.04 TLS。但是按照网上的说法,他们更加推荐20.04 TLS。不过我使用22.04没有出过什么问题。
在安装系统的时候,推荐划出一个专门的分区给LLM(或专门的硬盘)。
3. 配置环境
3.1. 预先准备
安装驱动前一定要更新软件列表和安装必要软件、依赖(必须)。
sudo apt-get update
sudo apt-get install g++
sudo apt-get install gcc
sudo apt-get install make如果你之前有安装过 NVIDIA 驱动或者 CUDA 程序的话,那么在安装之前需要先卸载之前的驱动和 CUDA 程序,否则可能会导致安装失败。卸载命令如下:
sudo apt autoremove nvidia* --purge
如果你之前是使用 NVIDIA 官方提供的run文件安装的驱动和 CUDA 程序的话,还需要使用以下命令进行完整卸载:
sudo /usr/bin/nvidia-uninstall
# 注意将下面的X和Y替换成你的 CUDA 版本
sudo /usr/local/cuda-X.Y/bin/cuda-uninstall执行完以上命令后,你的系统就变成了一个”干净”的系统,可以开始安装了。
3.2. 安装CUDA
首先进入NVIDIA CUDA 版本列表页面,找到你需要的 CUDA 版本。
因为VLLM是一个高速更新的项目,所以一版选择最新的CUDA即可,进入版本的下载页面,选择对应的操作系统、架构、操作系统、版本,安装方式,就可以看到相应的安装命令。

按照官网上的操作执行即可。在安装过程中,便可以把驱动给一起装了,我个人就是这么做的。如果你有独特的要求,也可以单独安装驱动。
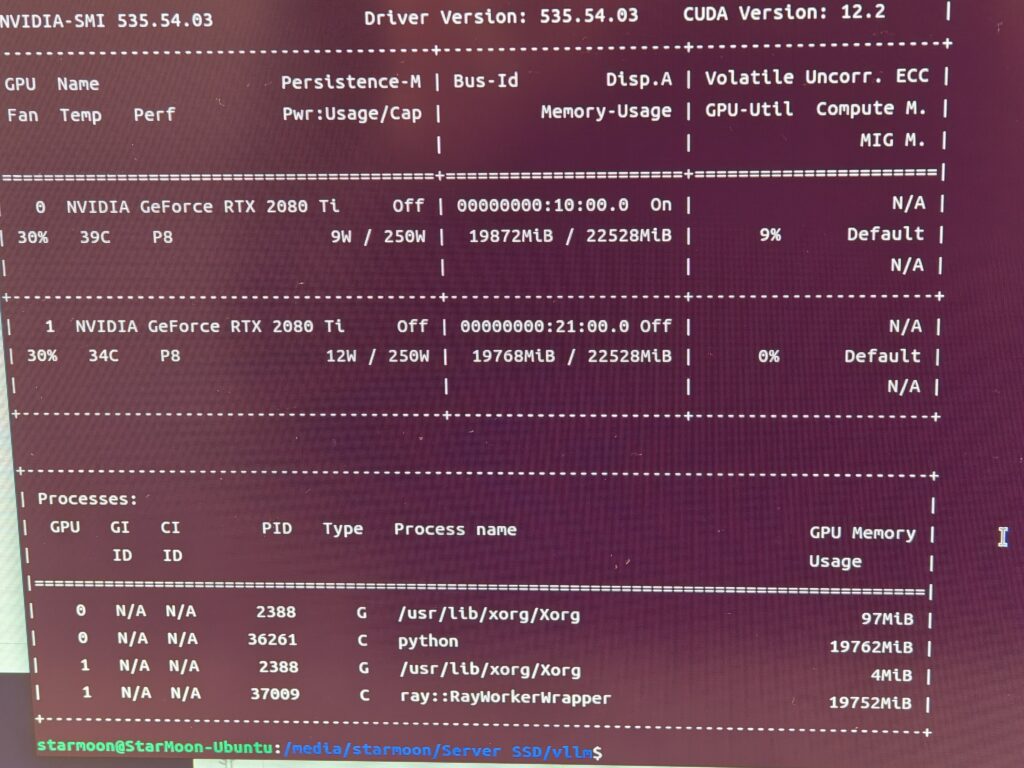
安装完成后,我们就可以在终端中直接使用nvcc --version命令来查看安装好的CUDA相关信息了。
如果同时安装了驱动,也可以使用nvidia-smi查看GPU信息。
3.2.1. 单独安装nVidia驱动(可选)
这一步的目的是在终端里输入nvidia-smi后,能够显示所有GPU的信息。
如果你真的什么都不知道,可以在Ubuntu软件和更新里安装驱动。
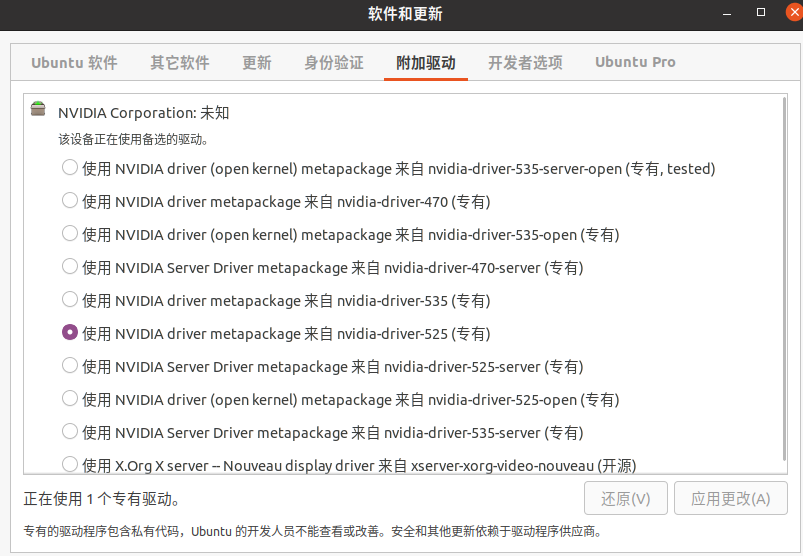
还有一个手动从官网下载和安装驱动的方法:
- 去官网下载对应驱动,把下载好的nvidia驱动放在英文名文件夹下。
- 禁用nouveau(nouveau是通用的驱动程序)。方法是编辑/etc/modprobe.d/blacklist.conf 或者(blacklist-nouveau.conf)(需要root权限),在文件末尾添加
blacklist nouveau和options nouveau modeset=0这两行,然后保存文件并且重新启动。 - 进入存放了驱动程序的文件夹,授予其可执行权限:
sudo chmod 777 NVIDIA-Linux-x86_64-xxx.xx.run - 执行安装命令:
sudo ./NVIDIA-Linux-x86_64-430.26.run - 按照提示操作
- 重启
之后,便可以通过执行nvidia-smi命令来检查显卡信息,以及nvidia-settings调出设置界面来配置显示相关选项了。
3.3. 安装conda
运行vllm需要Python环境,为了不扰乱系统原本的Python,我自己使用了Anaconda
- 去官网下载Anaconda,不用担心下载错了,官网会检测系统并且让你下载到正确的版本。
- 执行安装程序:bash ~/Downloads/Anaconda3-20xx.xx-Linux-x86_64.sh
- 按照提示操作,注意最后一步当安装程序询问你是否需要初始化Anaconda时,输入yes并回车来初始化Anaconda
3.4. 创建环境并安装依赖
按照文档里的说法,vllm对于系统的要求只是Linux,但对于Python则只支持3.8-3.11。
所以先创建一个基于python3.11的conda环境。
conda create --name vllm python=3.11--name后面的就是环境的名字,这里是vllm。后面的3.11指定了python版本是3.11。
然后切换到这个环境中:
conda activate vllm4. 安装vllm
首先切换到刚刚创建的conda环境中,执行下面的命令安装vllm:
pip install vllm在安装过程中出现网络错误是常有的事情,像什么time out/SSL error之类的。我个人的方法是使用代理服务器。clash for windows有linux版,可以像使用其他梯子一样在GPU服务器上使用它,也可以使用本地网络上的其他代理服务器提供一个基于LAN的http/https代理。
假设在局域网上有一台IP为192.168.200.210的电脑上安装了翻墙工具,并且在端口7890上开启了服务。那么在GPU服务器上只需要在终端里输入以下命令,就能让这个终端后面的网络活动走代理:
export http_proxy="http://192.168.200.210:7890/"
export https_proxy="https://192.168.200.210:7890/"这里简要说明一下我个人的意见。网上有不少教你换源或者使用镜像站安装python软件包以避免出现网络问题的教程。但是我个人觉得这么做容易产生版本问题(镜像站里没有你要的那个版本),所以如果不是因为做开发而经常安装Python软件包而只是用这么一次,还不如直接挂梯子省心。
5. 下载模型权重
可以直接从huggingface上下载模型,也可以从镜像站或者国内的魔搭社区下载。
几件咱觉得很有趣的事情:
- 国内的huggingface镜像站是完全同步huggingface.co的,不存在版本延迟,可以放心下载。
- huggingface.co被GFW屏蔽的方式是DNS污染+SNI重置。我之前通过修改hosts指定正确的IP+比特彗星设置下载失败重试的次数为9999次,然后软件不断地重试,最终成功直连并且下载到了模型。这只能说运气好。
- 接上一个,因为huggingface的屏蔽方式,或许可以通过反向代理+hosts/本地DNS服务器来绕过直GFW从而连它,但是我试过ngins和caddy均以失败告终。
- 魔搭的模型与huggingface上的可能会存在者“微小”的差距。我遇到一位群友就是在魔搭下载了模型,结果在text generation webui加载后发现这个模型无法自动停止输出。经过他的一番对比才最终发现与huggingface上的模型相比,魔搭社区同一模型仓库里的config.json里的eos_token_id不正确。
- 淘宝闲鱼等网站上有huggingface代理下载服务,收费帮助你下载模型。如果哪一天我厌烦了这一切,可能会付钱请他们帮忙下载......
下载模型的时候,注意区分模型的格式。vllm不支持llama.cpp格式(GGUF或GGML)的模型。别的transformer/GPTQ/AWQ量化等都支持。
在模型规模选择上,咱建议量力而行,别把显存撑爆了。这儿的小工具可以帮助计算LLM的显存消耗。
下载模型,一版需要完整下载仓库里的所有文件。
需要把下载好的模型权重放入不含有汉字的路径。
6. 运行推理服务
为了对外提供服务,需要以serving模型启动vllm。
这是一个示例的启动命令,启动后会在服务器本地所有网卡获得IP的8080端口提供兼容Openai API规范的API。
python -m vllm.entrypoints.openai.api_server \
--model="/home/Qwen1.5-32B-Chat" \
--tensor-parallel-size 2 \
--trust-remote-code \
--device auto \
--gpu-memory-utilization 0.98 \
--dtype half \
--kv-cache-dtype fp8 \
--served-model-name "Qwen1.5-32B-Chat" \
--host 0.0.0.0 \
--port 8080我在这里使用的各个启动参数的含义:
| model | 模型路径,以文件夹结尾 |
| tensor-parallel-size | 张量并行副本数,即GPU的数量,咱这儿只有2张卡 |
| trust-remote-code | 信任远程代码,主要是为了防止模型初始化时不能执行仓库中的源码,默认值是False |
| device | 用于执行 vLLM 的设备。可选auto、cuda、neuron、cpu |
| gpu-memory-utilization | 用于模型推理过程的显存占用比例,范围为0到1。例如0.5表示显存利用率为 50%。如果未指定,则将使用默认值 0.9。 |
| dtype | “auto”将对 FP16 和 FP32 型使用 FP16 精度,对 BF16 型使用 BF16 精度。 “half”指FP16 的“一半”。推荐用于 AWQ 量化模型。 “float16”与“half”相同。 “bfloat16”用于在精度和范围之间取得平衡。 “float”是 FP32 精度的简写。 “float32”表示 FP32 精度。 |
| kv-cache-dtype | kv 缓存存储的数据类型。如果为“auto”,则将使用模型默认的数据类型。CUDA 11.8及以上版本 支持 fp8 (=fp8_e4m3) 和 fp8_e5m2。ROCm (AMD GPU) 支持 fp8 (=fp8_e4m3) |
| served-model-name | 对外提供的API中的模型名称 |
| host | 监听的网络地址,0.0.0.0表示所有网卡的所有IP,127.0.0.1表示仅限本机 |
| port | API服务的端口 |
详细的启动参数参见文档里的说明。文档里还包含了Lora、随机种子、序列与上下文长度、日志等功能设置
7. 安装dify
dify文档里最推荐的是基于Docker部署。所以需要先安装Docker环境。这里可以在同一台服务器上部署,也可以在不同的服务器上部署。
7.1. 安装docker
docker官网上有各个操作系统的详细安装说明,这里以Ubuntu为例,首先需要更新APT,然后安装Docker官方GPG KEY:
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc接着,添加官方存储库并更新源数据:
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update然后,直接安装Docker和docker-compose:
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin接下来,可以尝试运行一个官方示例容器来测试docker能否正常工作:
sudo docker run hello-world7.2 部署dify
这一部分可以参考DIFY官网的部署说明。
下面是一个最简单的部署方式,咱也是这么做的。
便是先找一个空文件夹,将dify源码拉取下来:
git clone https://github.com/langgenius/dify.git如果你的服务器上没有git,可以使用以下命令安装它:
sudo apt-get install git进入 dify 源代码的 docker 目录,执行一键启动命令:
cd dify/docker
docker compose up -d最后检查是否所有容器都正常运行:
docker compose ps包括 3 个业务服务 api / worker / web,以及 4 个基础组件 weaviate / db / redis / nginx。
接下来,你便可以通过服务器浏览器访问http://localhost来访问dify了。
可以自行改造docker compose文件和环境变量以实现特定端口/局域网部署。
8. 使用dify搭建工作流
8.1. dify接入vllm
使用管理员身份登录dify后,能够在设置—-模型供应商那里填入与OpenAI API相兼容的API。
依照之前vllm启动参数里的信息,填入模型名称、API URL和上下文长度、最大token上限。
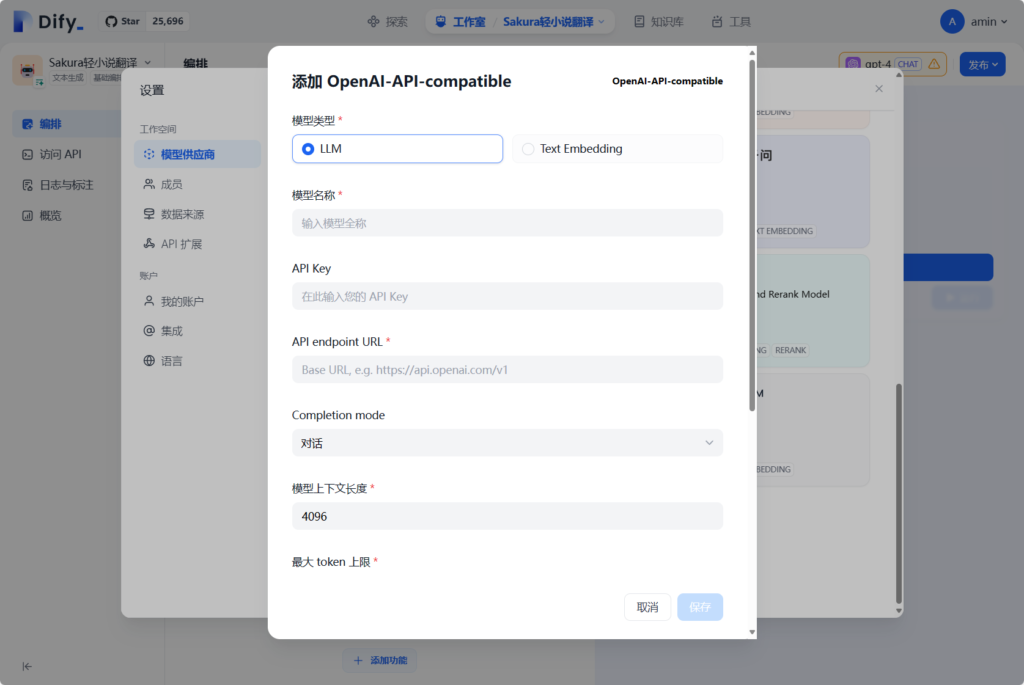
如果这一步无法进行保存,就检查部署了vllm的服务器上是否允许了防火墙,本地网络连接是否正常,URL和模型名称是否正常。
一般情况下,如果顺利保存了模型,那么就可以创建应用了。
8.2. 创建dify应用
原本这里写了一大堆,但是感觉都不合适,所以还是删掉了,感觉大家还是都去看文档比较好2333
dify上的工作流中有很多实用的插件。
这是咱自己创建的一个翻译应用的实例中的模板转换部分:
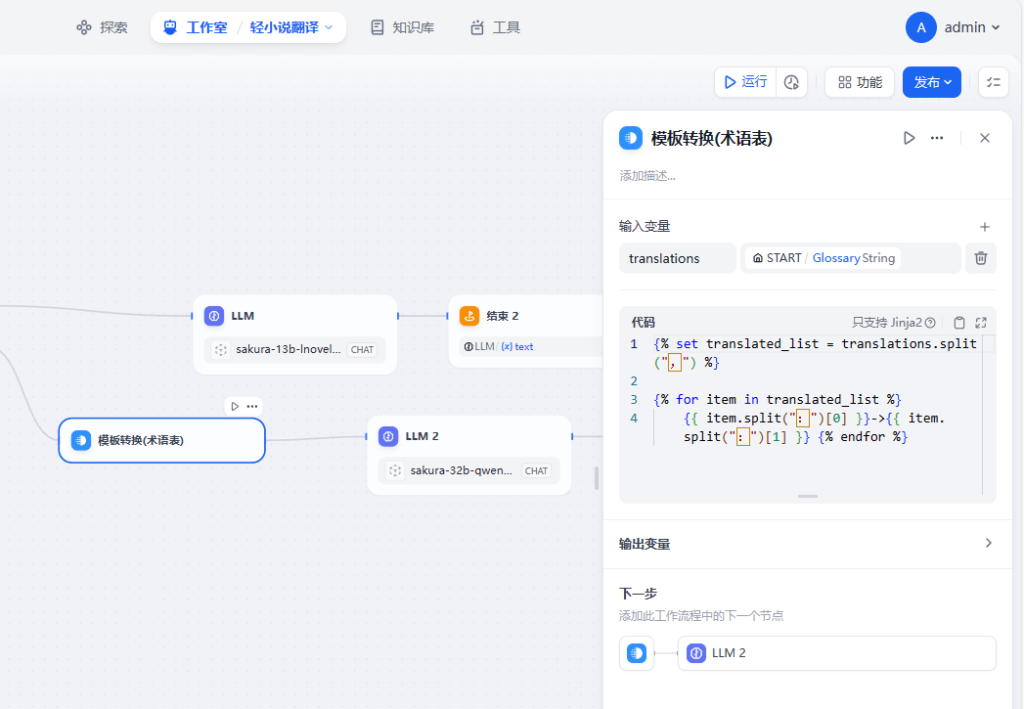
因为vllm和dify都处于高速的进化之中,这里的示例可能不具备足够的时效性(咱是五月初就搭建了这一套系统来玩玩的,但是双卡还是不够跑超大型LLM于是这一套系统就被尘封了,直到今天才想起来自己已经半年没有更新过博客了,于是把这东西拿出来写了点)。
Comments 2 条评论
这是一条私密评论
这是一条私密评论