
VITS可以使用其他人的语音数据进行训练,最终得到自己喜爱的人物的TTS音色。
这次我使用的是经过CjangCjengh修改的VITS模型。
由于我本身做的试验不多,所以难免有错误,希望指正。
这次搭建之中还是踩了不少坑的,由于这个仓库没有issue,我只能一个个尝试了。
首先,还是去把CjangCjengh/vits下载到本地,git clone也行。
然后,你需要安装python3.7。虽然READ.ME说推荐3.7,但是我的python3.10实测不成功。如果你的电脑已经安装了别的python版本,那么可以尝试一下我的方法:给python3.7另选个目录。安装时注意不要将其添加到path,最后记住安装位置。之后需要用到python3.7的地方,比如说vits-main目录的时候,你可以打开cmd,输入:set path=C:\Softs\Python37;C:\Softs\Python37\Scripts;%path%
这里的C:\Softs\Python37就是你的安装位置。如果是powershell,可以使用$env:path=“C:\Softs\Python37;C:\Softs\Python37\Scripts;”
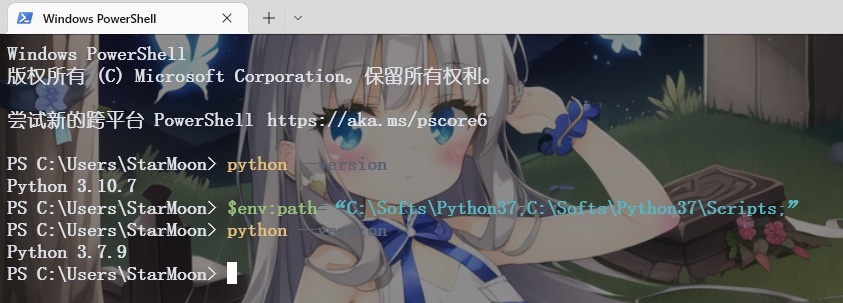
之后,你就可以按照说明文件 pip install -r requirements.txt 来安装依赖。
为了保险,建议在这一步使用clash等扶墙工具以保证不出现网络问题。
接下来,需要准备数据集。我这里准备是单人数据集。数据集有以下几个要求:1、必须一句或者一小段一个音频文件。2、准备好的语音需转换成wav格式,单声道,采样率必须为22050Hz,PCM 16bit。 3、准备好文本台词,将音频文件放入名为wav的文件夹里,而台词则必须放入一个txt文本文件,且每一行台词和音频文件都必须一一对应。

如果你要训练vits多人模型,数据集中的语音列表文件略有变化,变化如下。

这里的“店员”、“顾客”就是speaker,对应的ID是“0”、“1”。
在完成了上述准备之后,还需要修改程序来让它能够在Windows下正常运行。
用vscode或者pycharm之类的工具打开train.py。在加载模块那里加上import os,下面加上os.environ["PL_TORCH_DISTRIBUTED_BACKEND"] = "gloo"
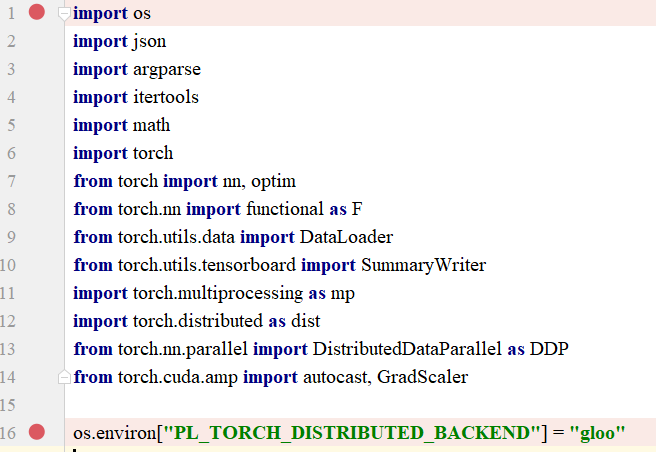
往下翻,把nccl改为gloo。

在这行上面一点的地方,把端口改成一个可用的端口。
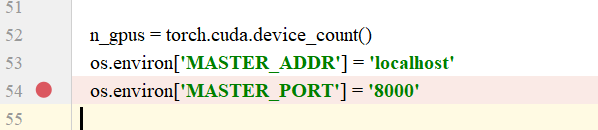
注意这是训练单人模型的train.py。如果需要训练多人模型,也需要自行修改train_ms.py。
理论上接下来就可以准备配置文件和准备训练了,不过这里很容易遇到一些问题,所以我提前提出来。
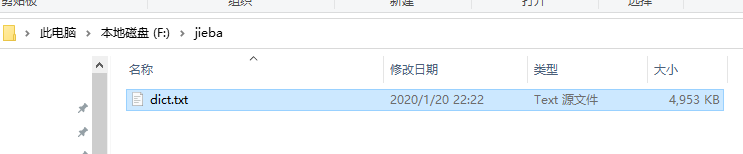
1、有可能你需要放置一些文件。需要在C盘和放了vits-main的目录(我是F盘)根目录和vits-main下新建一个jieba文件,然后去jieba的安装文件夹(我这里是C:\Softs\Python37\Lib\site-packages\jieba)下面复制dict.txt到新建的jieba下(例如F:\jieba)和vits-main下面的jieba文件夹下(F:\AI-AUDIO\vits-CjangCjengh-main\vits-main\jieba)。

2、有可能你需要关闭上海话和客家话的cleaner。不然在训练之前Opencc会报错找不到客家话和上海话的配置文件。(OpenCC('zaonhe')之类的)。我找遍了全网,也没找到zaonhe.json这样的配置文件,所以最后只好关闭了这两种语言的clean。具体操作是打开vits-main\text下面的cleaners.py,注释掉包含shanghainese、cantonese、SH、GD的行。


这之后,READ.ME还提到了一个预处理的过程,不过我没有将这个过程与分开,而是通过修改配置文件将这两个过程进行了融合。
所以接下来就是生成配置文件的过程。首先,我们从vits-main\configs里复制一份配置文件,然后打开,开始编辑这个配置文件。

log_interval:保存间隔;seed:种子数,相同的种子和数据集可以得出相同的模型参数;epoch:训练多少个循环;learning_rate:学习率;batch_size:批大小,建议参考自己的显存大小设置,示例,我设置24可以吃掉近10G显存;fp16_run:是否使用半精度进行训练,使用可以节约显存并适当加快速度,具体参照自己显卡的fp16算力;

training_files:用于训练语音文本文件;validation_files:用于评估效果的语音文本文件;text_cleaners:语音cleaners,选择对应于语音语言的clezners;n_speakers:语音包括的人数。单人需要填0;cleaned_text:数据是否经过预处理,如果经过处理填写true,没有做过处理则填入false。

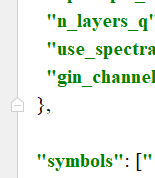
speakers:填写人物的名字或者代号,如果只打算训练一名人物,就不需要填写speakers这行,可以直接删除;symbols:填写一些非当前语言的文字,或者会涉及语气的标点符号。
当一切准备好的时候,便可以准备训练了。打开终端,设置环境为python3.7,进入vits-main目录,然后输入python train.py -c ./configs/zh_ofs_model_config.json -m ./OFS(这里是单人训练,多人训练需要改用train_ms.py,./configs/zh_ofs_model_config.json是配置文件的位置,OFS是模型的名字,也是训练过程中的模型参数保存的地方)
模型在训练的过程中会把过程中的模型参数文件保存在指定的地方。大致结构如下。

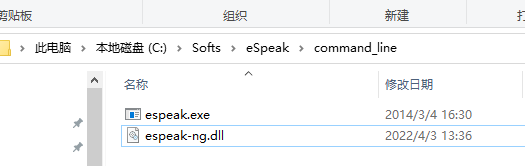
当你想测试效果时,就需要在Jupyter Notebook打开vits-main下面的inference.ipynb来生成语音。不过在这之前你需要安装eSpeak和eSpeak-ng,然后将espeak-ng.dll复制到Espeak安装目录下的command_line文件夹中。最后将这个目录添加到path环境中。
但是这样还是会产生错误,所以我参考了这篇专栏文章里的做法,注释掉 site-packages\phonemizer\backend\espeak\base.py里面的那几行检测代码。不过或许是版本不同,我注释的的是site-packages\phonemizer\backend\base.py里面的41-44行。

就下了就可以安装juypter notebook了。命令行pip install juypter,安装完成后直接输入juypter notebook就可以运行juypter notebook了。但是这样它的主目录不在vits-main目录。需要将这下面的文件复制到默认的主目录,或者变更主目录。
需要变更主目录,首先输入jupyter notebook --generate-config来生成配置文件,然后修改配置文件的地址,改为vits-main目录。之后再启动jupyter notebook 。
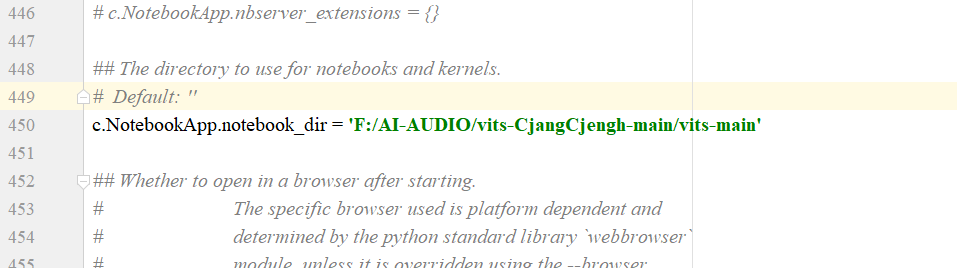
这里注意,斜杠得用"/",不能用“\”。启动jupyter notebook 然后在浏览器里打开inference.ipynb,按顺序运行代码。不过有些地方需要改一下。这里还是单人模型的调用,因为我没用训练过多人模型。
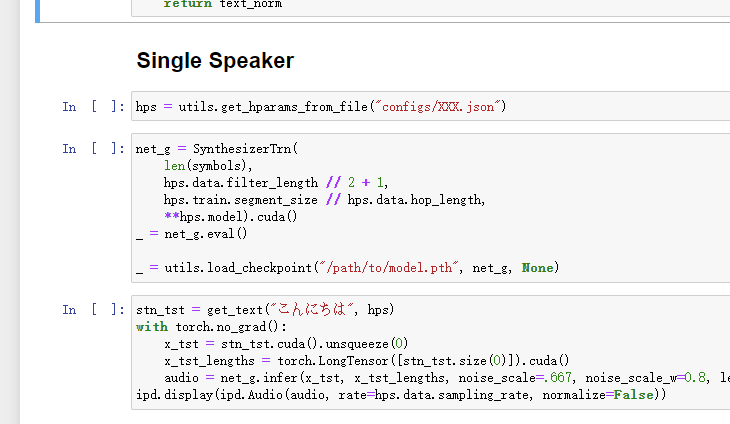
configs/XXX.json改成配置文件的位置;/path/to/model.pth改成你的模型参数保存的位置,使用G和D都行;こんにちは改成你要转换成语音的话。改好之后按照从上到下的顺序运行代码即可。
之后,下面会出现一个音频播放器,即可收听转录语音,或者下载保存成文件。
Comments 5 条评论
背景图片真好看
求大佬指教
跟requirements.txt安裝了 torch 1.6.0, 執行train.py時報錯
AttributeError: module ‘torch.distributed’ has no attribute ‘init_process_group’
聽說 1.6.0 不能在windows上跑 torch.distributed
更新到 1.7, 1.8 則出現其他問題:
RuntimeError: "fill_cuda" not implemented for ‘ComplexHalf’
大佬有遇到這個情況嗎 ?
大佬有空吗?请问4核CPU,8G内存够跑这个吗?
@接受 没有GPU的话…会很痛苦的。你调小一些bs应该也行吧….就是不要指望速度了。
有关zenohe.json的网址 https://huggingface.co/spaces/skytnt/moe-tts/commit/fb9594320e710850c698d8c9e6644afd30605ee0